Nívea Bispo | 09/09/2016
Como ler bases de dados no R de maneira rápida e eficiente?

Existem pacotes na base do R mais comumente usados para ler (e/ou criar) arquivos de dados com diferentes extensões (.txt, .csv, .xls, .sav, .dta, .sas, etc). Os comandos mais usuais são o ‘read.table’, ‘read.csv’ e o ‘read.delim’, todos do pacote utils. Para a lei-tura de extensões diferentes das usuais, como por exemplo, .xls, .sav, .dta , .sas, há tam-bém alguns pacotes disponíveis: gdata (.xls), foreign (.dta) e Hmisc (.sav, .sas).
Se há opções disponíveis, por que usar pacotes como o data.table, readr, readxl e haven, para leitura e manipulação de bases de dados no R?
Antes de falar dos pacotes, algumas definições…
- Arquivos no formato delimitado: São arquivos onde qualquer caracter pode ser usado para separar os termos. Os delimitadores mais usuais são: vírgula, espaço e : . Arquivos com este tipo de extensão terão suas colunas separadas por um delimitador.
- Arquivos no formato de largura fixa: São arquivos onde as colunas são definidas pela posição dos caracteres nos arquivos.
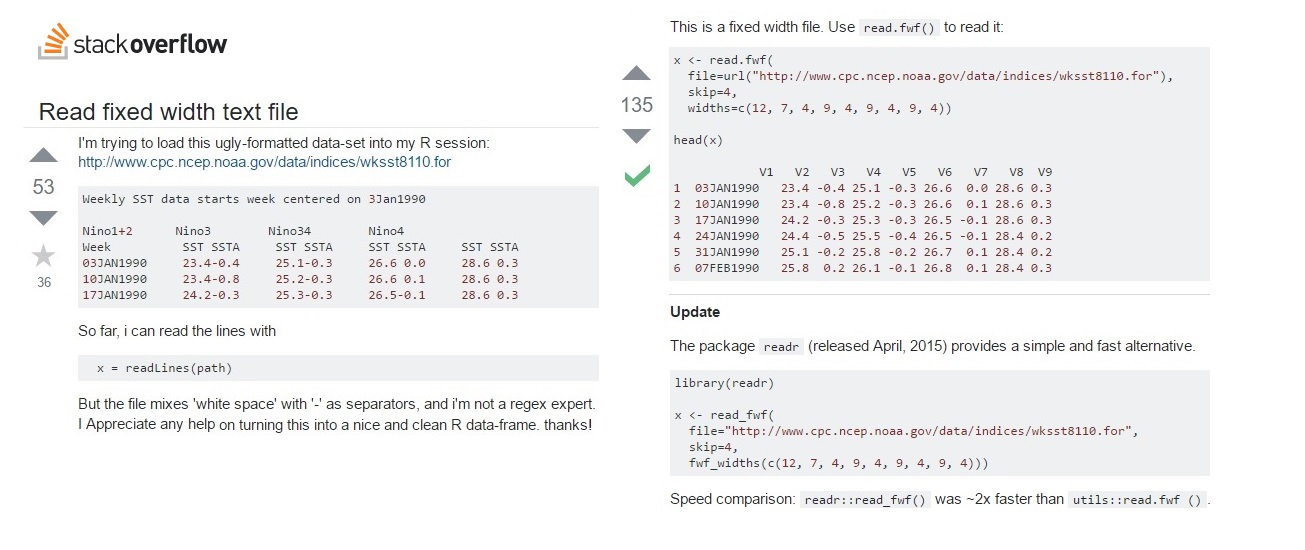
- link da base mostrada na figura acima: http://www.cpc.ncep.noaa.gov/data/indices/wksst8110.for.
data.table
Pacote criado por Matt Dowle (autor) e Arun Srinivasan (co-autor).
- O que faz?
- Fornece uma versão melhorada do comando ‘data.frame’, permitindo ao usuário manipular/criar bases de dados mais rapidamente;
- É especialmente útil para manipulação de grandes bases de dados (por exemplo, 1 GB para 100 GB na memória RAM).
- Objetivos?
- Reduzir o tempo de programação (como? Chamando menos funções na execução de algum comando);
- Reduzir o tempo de computação (como? Permitindo uma rápida agregação e atualização por referência).
- Sintaxe:
DT[i,j,by].
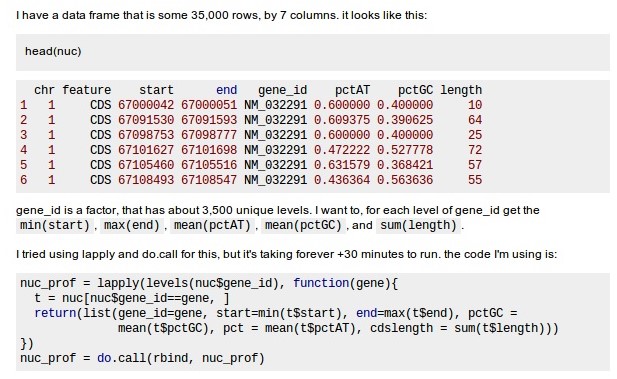
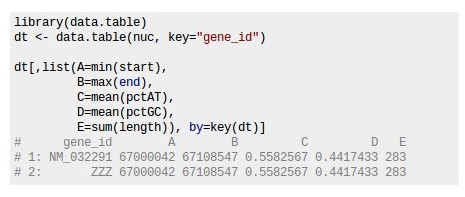
Outra vantagem do pacote está na velocidade (em grandes bases de dados ele chega a ser 10x mais rápido que as funções usuais) com que ele lê a base de dados.
## Por exemplo, suponha uma base com extensão .csv contendo 1 milhão de linhas e 6 colunas (50MB). Se usarmos:
#read.csv("teste.csv") # time: 30-60 s
#fread("teste.csv") # times: 3sou
## outra base contendo 200 milhões de linhas e 16 colunas (20GB):
#read.csv("big.csv") # time: ~ 1h
#fread("big.csv") # time: ~ 10 minAfinal, como utilizar o comando DT[i,j,by], e o que faz cada um dos seus índices?
Outras funções importantes do pacote são:
- fread: Similar ao read.table, porém mais rápido. Argumentos como sep, colClasses e nrows , são detectados de forma automática. Esta função é para leitura de arquivos delimitados.
- merge: Faz o merge de 2 arquivos data.table.
- setDT : Converte listas e arquivos no formato data.frame, em arquivos no formato data.table, usando referência.
require(data.table)## Loading required package: data.tabledt1 <- data.table(A = letters[1:10], X = 1:10, key = "A")
dt2 <- data.table(A = letters[5:14], Y = 1:10, key = "A")
m<-merge(dt1, dt2,all = TRUE)
print(m)## A X Y
## 1: a 1 NA
## 2: b 2 NA
## 3: c 3 NA
## 4: d 4 NA
## 5: e 5 1
## 6: f 6 2
## 7: g 7 3
## 8: h 8 4
## 9: i 9 5
## 10: j 10 6
## 11: k NA 7
## 12: l NA 8
## 13: m NA 9
## 14: n NA 10X = data.frame(A=sample(3, 10, TRUE), B=sample(letters[1:3], 10, TRUE), C=sample(10),stringsAsFactors=FALSE)
print(X)## A B C
## 1 2 a 1
## 2 3 a 8
## 3 3 b 9
## 4 2 a 3
## 5 3 c 2
## 6 2 b 5
## 7 3 c 7
## 8 2 c 6
## 9 1 b 4
## 10 1 c 10newX<-setDT(X)[, .N, by=.(A,B)]
print(newX)## A B N
## 1: 2 a 2
## 2: 3 a 1
## 3: 3 b 1
## 4: 3 c 2
## 5: 2 b 1
## 6: 2 c 1
## 7: 1 b 1
## 8: 1 c 1readr
Pacote para leitura de bases de dados criado por Hadley Wickham.
- O que faz?
- Lê bases de dados nos formatos .txt, .csv, .fwf e .log, com uma velocidade 10x maior que comandos usuais. No readr não há a necessidade de converter os caracteres em fatores usando
stringAsFactors = FALSE.
- Objetivo?
- Fornecer uma maneira rápida e amigável para leitura de dados no R.
- Principais comandos:
read_delim(), read_csv(), read_tsv(), read_csv2()read_fwf(), read_table()read_log()read_file() ## lê um arquivo em uma *string*.
- Algumas curiosidades:
- Lê arquivos .csv dentro de um data frame usando o
read_csv().
require(readr)## Loading required package: readrmtcars_path <- tempfile(fileext = ".csv")
write_csv(mtcars, mtcars_path) ## salva um data frame no formato de arquivo delimitado
mt<-read_csv(mtcars_path)## Parsed with column specification:
## cols(
## mpg = col_double(),
## cyl = col_integer(),
## disp = col_double(),
## hp = col_integer(),
## drat = col_double(),
## wt = col_double(),
## qsec = col_double(),
## vs = col_integer(),
## am = col_integer(),
## gear = col_integer(),
## carb = col_integer()
## )print(mt)## # A tibble: 32 × 11
## mpg cyl disp hp drat wt qsec vs am gear carb
## <dbl> <int> <dbl> <int> <dbl> <dbl> <dbl> <int> <int> <int> <int>
## 1 21.0 6 160.0 110 3.90 2.620 16.46 0 1 4 4
## 2 21.0 6 160.0 110 3.90 2.875 17.02 0 1 4 4
## 3 22.8 4 108.0 93 3.85 2.320 18.61 1 1 4 1
## 4 21.4 6 258.0 110 3.08 3.215 19.44 1 0 3 1
## 5 18.7 8 360.0 175 3.15 3.440 17.02 0 0 3 2
## 6 18.1 6 225.0 105 2.76 3.460 20.22 1 0 3 1
## 7 14.3 8 360.0 245 3.21 3.570 15.84 0 0 3 4
## 8 24.4 4 146.7 62 3.69 3.190 20.00 1 0 4 2
## 9 22.8 4 140.8 95 3.92 3.150 22.90 1 0 4 2
## 10 19.2 6 167.6 123 3.92 3.440 18.30 1 0 4 4
## # ... with 22 more rows- Se algum problema surgir ao tentar analisar a base de dados, a função read_ retornará um aviso informando quantos problemas existem.
df <- read_csv(col_types = "dd", col_names = c("x", "y"), skip = 1,
"1,2
a,b")## Warning: 2 parsing failures.
## row col expected actual file
## 1 x a double a literal data
## 1 y a double b literal dataproblems(df)## # A tibble: 2 × 5
## row col expected actual file
## <int> <chr> <chr> <chr> <chr>
## 1 1 x a double a literal data
## 2 1 y a double b literal data- Comparado ao comando fread do pacote data.table, o readr:
- É mais lento (cerca de ~1.2-2x mais). Portanto, se quiser um melhor desempenho, use o fread;
- O fread salva o trabalho de forma automática, “adivinhando” o tipo de delimitador. Já o readr te força a definir esses parâmetros;
- O readr foi projetado (em C++ e Rcpp) para ser o mais geral possível, enquanto o fread foi projetado (em C) para ser o mais rápido possível na leitura.
comments powered by Disqus